Tailoring Mechanisms
Change History
| Id | Subject | Date |
| Latest Commit | Removed review markers. | 2022-10-21 |
| KBLFRM-1057 | Included Tailoring Concept for custom XSD 1.1 Assertions | 2022-02-11 |
| KBLFRM-989 | Created Implementation Guideline for Tailoring Mechanisms | 2020-10-21 |
Motivation and Objective
The VEC provides a comprehensive model for the digital description of a wide variety of information and their relationships to each other in the context of the electrical system development process. Despite the striving for the greatest possible semantic precision, the demand for general applicability of the standard means that, at various points restrictions cannot be formulated to the same extent as it would be possible in the context of a very specific use case or a company context. This applies to the following examples, among others:
- The set of valid model elements: Probably no use case requires all 450+ classes of the VEC at the same time and the set of required model elements is highly dependant from the use case itself.
- Valid values for attributes: The allowed patterns and / or discrete values (enumerations) of attributes can depend on a specific use case or company context and can even change over time (e.g. new technologies)
- The balance between mandatory and optional information: The amount and completeness of information contained in a VEC depends on the use case and process. While it might perfectly ok the have some missing information in an early phase of the process, it might intolerable at a later stage.
This implementation guideline presents three approaches for adapting the model to address the above issues in specific application scenarios, while still maintaining compatibility with the standard:
- Custom Open Enumerations: New literals can be added to open enumerations (see Open and Closed Enumerations)
- XSD 1.1. Assertions: The schema can be enriched with assertions to be more restrictive.
- Schema Filtering: With “Schema Filtering” the schema can be made less extensive and by this also more restrictive (Less allowed classes, attributes etc.).
All these approaches have in common, that the schema of the standard is adapted / modified in a suitable form. The result is a tailored “VEC” schema that is specific for the use case, but still compatible with the regular VEC schema.
This Implementation Guideline explains how these modifications can be achieved in an efficient way based on XSLT. XSLT is a useful technology, when:
- you want to modify XML data,
- you can define the modification based on rules,
- the general structure of your result is close to the input,
- and performance is not critical.
This makes it the perfect solution for this use case, where we want to modify the XML Schema of the VEC at very specific locations while keeping the rest unchanged.
General Concept

The general concept is illustrated in the figure above. The customization rules are defined in an “compiler XSL-file”. This file defines how the extensions are made in the schema syntactically. It compiles the customizations into an existing schema. For example, in case of open enumerations, the compiler file defines at which position in XSD new literals are to be inserted. The compiler files are universal and independent of the specific context (e.g. company, use case) of the customization. For open enumerations and assertions such compiler files are provided here.
The actual customizations are defined in an external XML data file (Customization Definition in the figure above). For example, in case of open enumerations, the data file defines which enumerations should be extended with which literals. This information is specific to the customization context and has to be created by oneself during the customization process. The syntax of the data file depends on the compiler file, but is usually trivial.
To create a custom VEC schema, the desired schema variant (strict or not) of the underlying VEC version is passed into a XSLT transformation pipeline, with the Compiler XSL as transformation. The data file is side loaded from the Compiler XSL.
Run the Transformation
java -cp /path/to/saxon.jar net.sf.saxon.Transform \
-xsl:./path/to/compiler.xsl
-s:/path/to/vec.xsd
-o:/path/to/result.xsd
data-file=url-to-data-file.xml
If the url-to-data-file.xml is a relative path, then it is relative to the compiler.xsl. The easiest way is to place required files (including the data file) in the current working directory.
Open Enumerations
Open Enumerations are a concept in the VEC to have predefined values for attributes, whilst being open for extension (for details see the corresponding recommendation chapter Open and Closed Enumerations). Two schema variants are provided officially for the VEC: the regular and the strict schema. The regular schema can be used for pure syntax validation of VEC files. However, it makes no restrictions for the use of values in attributes with an open enumeration type. The strict schema restricts these attributes to have only values that are defined literals from the VEC standardization board in the corresponding open enumeration. The advantage of using the strict schema is that you are able to validate that only defined literals have been used.
However, if you extend1 an open enumeration with new literals, e.g. for your process specific requirements, or new wiring harness technologies, then the strict schema validation will break. In this case it is not possible anymore to check if only defined values, either by the standard or the process, have been used. Nevertheless, it would be highly appreciable to still have such a mechanism in place. To achieve this, you need an extended strict schema, that includes the values from the standardization board and the process specific values. This implementation guideline is about creating such an extended strict schema.
What you need
The generation of such an extended strict schema is done as described in section General Concept. As input, you need:
- The Compiler XSL: vec-open-enum-compiler.xsl
- A definition of your enumeration extensions, an example can be found here: enum-literals.xml
Define new Enumerations
The enum-literals.xml (link above) file contains examples on how to add custom enumerations.
<?xml version="1.0" encoding="UTF-8"?>
<enum-profile>
<enum type="WireReceptionType">
<literal name="MyExampleLiteral">
My example description with html elements <br/>
</literal>
<literal name="MyExampleLiteral2" />
</enum>
<enum type="WireLengthType">
<literal name="MyExampleLiteral3">
My second example description
</literal>
</enum>
</enum-profile>
This example adds a literal with the name MyExampleLiteral to
WireReceptionType with a description (Note that it is possible to include html
tags) and a literal without a description named MyExampleLiteral2. It also
adds MyExampleLiteral3 to WireLengthType.
If a new VEC version is released, this file can be used recreate an updated company specific scheme (without having to repeat all changes manual).
Schema Assertions
XSD 1.1 introduced a concept to define Assertions within a XSD:
An assertion is a predicate associated with a type, which is checked for each instance of the type. If an element or attribute information item fails to satisfy an assertion associated with a given type, then that information item is not locally valid with respect to that type.
Assertions are defined as XPath 2.0 expressions that are evaluated to true or false. This makes it possible to express much more meaningful rules in the schema than it is possible with the pure syntax checking of XSD 1.0. In particular, it is not only possible to further restrict the multiplicities of attributes, but more complex conditions, such as dependencies between attributes, can be expressed (e.g. like “if type is ‘rectangle’ then count(sides) must be greater equal 4”).
The great benefit of this approach is, that these rules are validated during a regular schema validation with a standard XML Parser.
descendant nodes (see XPath Axes) of the context node can be used in the XPath expression. Functions like .., id() or idref() are not available.
What you need
The generation of such an asserted schema is done as described in section General Concept. As input, you need:
- The Compiler XSL: vec-assertions-compiler.xsl
- A definition your custom assertions, an example can be found here: data-profile.xml
Define Assertions
The data-profile.xml (link above) file contains examples on how to add custom assertions.
<?xml version="1.0" encoding="UTF-8"?>
<data-profile>
<context type="ConductorSpecification">
<rule test="CrossSectionArea">
All conductors shall specify a cross section area. The cross section area is an
important parameter for numerous design rules (e.g. aggregated cross section area
of splices).
</rule>
<rule test="CrossSectionArea/ValueComponent gt 0.0">
A conductor with cross section area not greater than 0 is non-existent.
</rule>
</context>
<context type="CavityAddOn">
<rule test="WireAddOn/ValueComponent gt 0.0"/>
</context>
</data-profile>
context type="..." defines the VEC class to which an assertion should be added. rule test="..." defines the XPath expression of the assertion that should be added to corresponding type. The above data-profile results in the following XSD:
<?xml version="1.0" encoding="UTF-8"?>
...
<xs:complexType name="ConductorSpecification" abstract="true">
<xs:complexContent>
<xs:extension base="vec:Specification">
<xs:sequence>
...
</xs:sequence>
<xs:assert test="CrossSectionArea">
<xs:annotation>
<xs:documentation xml:lang="en"> All conductors shall specify a cross section
area. The cross section area is an important parameter for numerous design
rules (e.g. aggregated cross section area of splices). </xs:documentation>
</xs:annotation>
</xs:assert>
<xs:assert test="CrossSectionArea/ValueComponent gt 0.0">
<xs:annotation>
<xs:documentation xml:lang="en"> A conductor with cross section area not greater
than 0 is non-existent. </xs:documentation>
</xs:annotation>
</xs:assert>
</xs:extension>
</xs:complexContent>
</xs:complexType>
...
Schema Filtering
The VEC is a comprehensive model with a variety of classes and attributes. In very few cases all of them are needed at the same time. For this reason it may be desirable to restrict the number of valid schema elements for specific interfaces. Schema Filtering can be useful in these cases.
For example, an interface for the exchange of UsageNodes would only require a handful of VEC core classes. Another scenario might be that you want to prohibit the use of CustomProperty in your own process. Many scenarios are conceivable, in the core it always burns down to limiting the power of the VEC purposefully to achieve a better controllability for certain use cases and interfaces.
Since the scenario of Schema Filtering is more complex and less straight forward, than the Open Enumerations scenario, the following section just provides an idea for a possible approach and not a “ready-to-use” solution.
The basic idea here is, that an XSLT script simply removes all unnecessary elements and leaves the rest unchanged. You can use either a positive or negative filter approach. In our example, we use a negative filter list (all elements on the list are removed). When removing a class it is not sufficient to only remove the class itself. All usages of the class must be removed as well. A class that has mandatory usages by other classes, can not be removed unless all usages are removed recursively till an optional point is reached.
The file vec-tailor-schema.xsl
contains an example on how to remove the Transformation2D from the VEC scheme.
The following snippet shows the relevant parts only. The rest of the XSLT script
is known known as
identity transformation
(copy of the source into the destination without changes).
The first line removes the class itself. The second line removes all optional
attributes with the type Transformation2D. If you validate the resulting
schema you can easily check if the Transformation2D has any mandatory usage
that have been overlooked (it has not).
...
<xsl:template match="xs:complexType[@name='Transformation2D']" />
<xsl:template match="xs:element[@type='vec:Transformation2D' and @minOccurs=0]" />
...
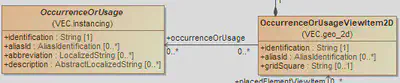
Unfortunately IDREF attributes cannot be handled in this fashion
automatically, but have to be checked manually. The figure on the right side
displays the occurrenceOrUsage association between
OccurrenceOrUsageViewItem2D and
OccurrenceOrUsage. Associations are translated into IDREF or
IDREFS in the XML Schema, in contrast to aggregations that are translated into
contained xs:element (compare
Mapping of the VEC Model to XML schema definition (XSD)).
The XML Schema representation of the association is the following:
<xs:complexType name="OccurrenceOrUsageViewItem2D">
<xs:complexContent>
<xs:extension base="vec:ExtendableElement">
<xs:sequence>
...
<xs:element name="OccurrenceOrUsage" type="xs:IDREFS" minOccurs="0"/>
...
</xs:sequence>
</xs:extension>
</xs:complexContent>
</xs:complexType>
That means a filtering rule cannot be formulated based on the target type of the association, as this type unknown in the XSD (in contrast to contained elements). Therefore a filtering rule must be more specific by explicitly addressing each relevant association, like this:
...
<xsl:template match="xs:element[@name='OccurrenceOrUsage' and
ancestor::xs:complexType[@name='OccurrenceOrUsageViewItem2D']]" />
...
Note: Make sure that the resulting schema remains compatible with the standard (XML Schema and Model Specification):
- Do not remove elements that are mandatory!
- Take extra care of usages via
IDREFassociations. These have to be checked in the model since the XML Schema is typeless for those associations.
-
Extension of open enumerations is perfectly valid as long as you adhere to the rules mentioned in the recommendation. ↩︎